The OCR function generates text of images and documents without embedded text. Several features use this generated text such as:
•Keyword searching
•Productions (exporting a separate .txt file for each document)
•Predictive Analysis (Gist)
For the generated text to be available for keyword searching the data must be re-indexed to add the newly generated text files to the index.
To access the OCR functions:
•Right-click on the filter tree and select "OCR..."
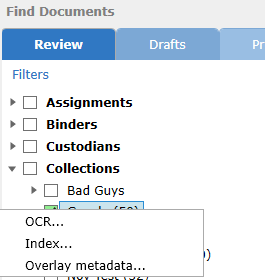
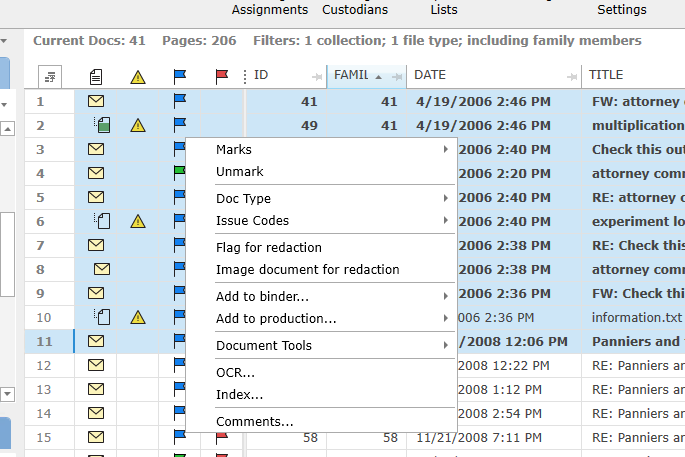
•Right-click one or more selected documents and select "OCR..."
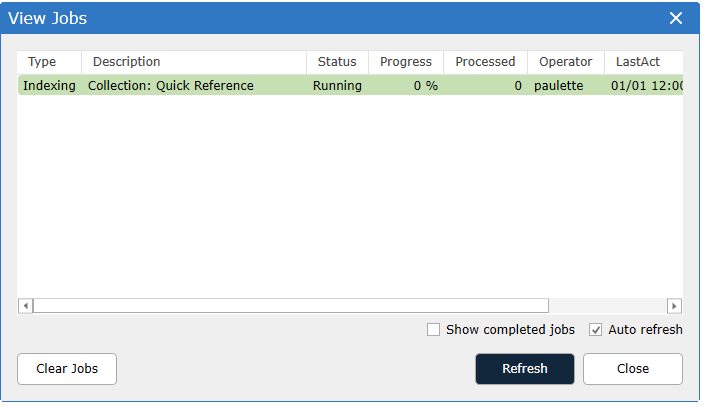
In the OCR dialog choose whether to overwrite existing OCR and click Run to start the OCR process. Always replace the OCR after redacting documents.
When data sets involve additional languages the OCR can be optimized to recognize those languages.
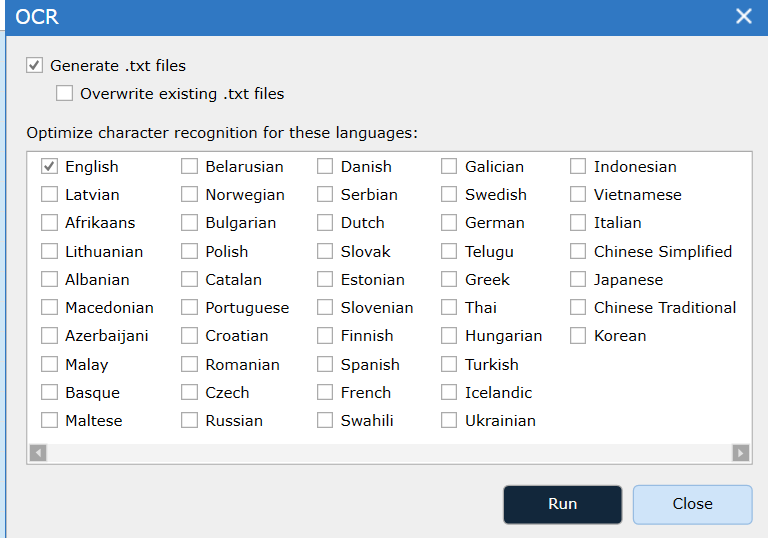
To monitor the progress go to the Process tab and select the View Jobs interface.